最近碰到一些问题涉及到二叉树,故写一篇博客便于记录。
“二叉树”的定义
“二叉树”是指每个节点拥有不超过 2 个分支的树状结构。 2 个分支称为“左树”和“右树”,其顺序不能随意更改。
二叉树的每一层(i)最多拥有 2i-1 个节点;
如果二叉树的深度为 k (定义根节点深度为 0),那么这个二叉树最多能拥有 2k+1-1 个节点;此时这个二叉树也叫“满二叉树”;
如果二叉树的深度为 k,当且仅当其中的每一个节点,都可以和同样深度的满二叉树,序号为 1 到 n 的节点一对一对应,此时这个二叉树称为“完全二叉树”,其总节点数 m 的范围为 2k-1 <= m <= 2k-1。
“二叉树”的存储
在程序语言中有各种方式实现二叉树,这里提一下比较常用的三种方式。
- 顺序存储:用数组或链接串列来存储,结构类似下图。
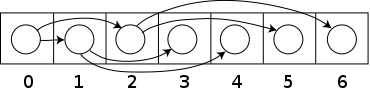
就是将二叉树的节点位置信息固定成数组的下标,好处是拥有更好的局部访问性,对于一个满二叉树,如果某个节点索引为 i,那么它的左子节点的索引是 2i+1,右子节点的索引是 2i+2,父节点的索引是|(i-1)/2|。这种存储方式在存储满二叉树时结构能最紧凑,但是在存储其它二叉树时,就会产生很多空白,造成空间浪费。
- 二叉链表:在拥有地址指针或者存储记录的语言中,可以用树状结构存储二叉树,数据结构如下图:

使用链表能避免顺序存储浪费空间的问题,算法和结构相对简单,但使用二叉链表,由于缺乏父链的指引,在找回父节点时需要重新扫描树得知父节点的节点地址。
- 三叉链表:在二叉链表的基础上增加了指向父节点的指针。
“二叉树”的遍历
二叉树的遍历方式有两种,一种是“广度优先遍历”,另一种是“深度优先遍历”。
广度优先遍历是指优先访问离根节点最近的节点,也称为按层次遍历,可通过队列算法实现。
深度优先遍历是指优先访问离根节点最远的节点,通过递归实现遍历。其中在深度优先遍历中,对访问节点值的处理顺序的不同,也分“前序”、“中序”和“后序”遍历。
“二叉树”构造
鉴于 JavaScript 中有数据引用,这里我们只实现二叉链表存储的满二叉树,代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Binary Tree Sort</title>
</head>
<body>
<p>生成二叉树</p>
<script>
function genFullBinaryTree(h = 0, value = 'root') {
if (h > 0) {
return {
value: value,
left: genFullBinaryTree(h - 1, `${value}_left`),
right: genFullBinaryTree(h - 1, `${value}_right`)
}
} else {
return;
}
}
console.log(genFullBinaryTree(5))
</script>
</body>
</html>
“二叉树”遍历的JS实现
-
广度优先遍历
广度优先遍历是优先遍历本层节点,遍历完成后再进行下一层节点遍历,可通过队列方式实现,代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Binary Tree</title>
</head>
<body>
<p>广度优先遍历满二叉树</p>
<div id="result"></div>
<script>
function genFullBinaryTree(h = 0, value = 'root') {
if (h > 0) {
return {
value: value,
left: genFullBinaryTree(h - 1, `${value}_left`),
right: genFullBinaryTree(h - 1, `${value}_right`)
}
} else {
return;
}
}
const bt = genFullBinaryTree(5)
const result = document.getElementById('result')
// 广度优先遍历
function breadthFirstSearch(root) {
const nodes = [root]
while(nodes.length) {
const node = nodes.shift()
const p = document.createElement('p')
p.innerText = node.value
result.appendChild(p)
if (node.left) {
nodes.push(node.left)
}
if (node.right) {
nodes.push(node.right)
}
}
}
breadthFirstSearch(bt)
</script>
</body>
</html>
-
深度优先遍历
深度优先遍历是优先访问子节点,因为对访问节点数据处理的不同,又分为“前序”、“中序”和“后序”,这里我们对这三种遍历方式进行实现。
- 前序遍历:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Binary Tree</title>
</head>
<body>
<p>深度优先遍历满二叉树</p>
<div id="result"></div>
<script>
function genFullBinaryTree(h = 0, value = 'root') {
if (h > 0) {
return {
value: value,
left: genFullBinaryTree(h - 1, `${value}_left`),
right: genFullBinaryTree(h - 1, `${value}_right`)
}
} else {
return {
value: ''
};
}
}
const bt = genFullBinaryTree(5)
const result = document.getElementById('result')
// 前序优先遍历
function DLRSearch(node) {
const p = document.createElement('p')
p.innerText = node.value
result.appendChild(p)
if (node.left) {
DLRSearch(node.left)
}
if (node.right) {
DLRSearch(node.right)
}
}
DLRSearch(bt)
</script>
</body>
</html>
- 中序遍历:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Binary Tree</title>
</head>
<body>
<p>深度优先遍历满二叉树</p>
<div id="result"></div>
<script>
function genFullBinaryTree(h = 0, value = 'root') {
if (h > 0) {
return {
value: value,
left: genFullBinaryTree(h - 1, `${value}_left`),
right: genFullBinaryTree(h - 1, `${value}_right`)
}
} else {
return {
value: ''
};
}
}
const bt = genFullBinaryTree(5)
const result = document.getElementById('result')
// 中序优先遍历
function LDRSearch(node) {
if (node.left) {
LDRSearch(node.left)
}
const p = document.createElement('p')
p.innerText = node.value
result.appendChild(p)
if (node.right) {
LDRSearch(node.right)
}
}
LDRSearch(bt)
</script>
</body>
</html>
- 后序遍历:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Binary Tree</title>
</head>
<body>
<p>深度优先遍历满二叉树</p>
<div id="result"></div>
<script>
function genFullBinaryTree(h = 0, value = 'root') {
if (h > 0) {
return {
value: value,
left: genFullBinaryTree(h - 1, `${value}_left`),
right: genFullBinaryTree(h - 1, `${value}_right`)
}
} else {
return {
value: ''
};
}
}
const bt = genFullBinaryTree(5)
const result = document.getElementById('result')
// 后序优先遍历
function LRDSearch(node) {
if (node.left) {
LRDSearch(node.left)
}
if (node.right) {
LRDSearch(node.right)
}
const p = document.createElement('p')
p.innerText = node.value
result.appendChild(p)
}
LRDSearch(bt)
</script>
</body>
</html>
三者的差别真的就只是对访问节点的处理顺序。
同时我们要知道,递归的本质是“循环+栈”操作,所以栈的高度与树的高度成正比,一旦二叉树的深度太大,很容易造成栈溢出。
如果每个节点都保存了对父节点的引用,那么我们就可以抛开栈,单纯地用循环来实现,比如下面用循环复用的方式实现:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Binary Tree</title>
<style>
.container {
display: flex;
}
.item {
flex-basis: 33.33%
}
</style>
</head>
<body>
<p>深度优先遍历满二叉树</p>
<div class="container">
<div class="item" id="DLR">
<p>前序遍历:</p>
</div>
<div class="item" id="LDR">
<p>中序遍历:</p>
</div>
<div class="item" id="LRD">
<p>后序遍历:</p>
</div>
</div>
<script>
function genFullBinaryTree(h = 0, value = 'root', parent) {
if (h > 0) {
const node = {
value: value,
parent: parent
}
node.left = genFullBinaryTree(h-1, `${value}_left`, node)
node.right = genFullBinaryTree(h-1, `${value}_right`, node)
return node
} else {
return;
}
}
const bt = genFullBinaryTree(5)
// 先序优先遍历
const dlr = document.getElementById('DLR')
function DLRSearch(node) {
let prev
let next
let current = node
while(current) {
// 如果上次遍历节点是当前节点的父节点
// 则开始当前节点子节点的遍历
if (prev === current.parent) {
const p = document.createElement('p')
p.innerText = current.value
dlr.appendChild(p)
prev = current
next = current.left
}
// 如果上次遍历节点是当前节点的左节点
// 则开始右节点遍历
if (!next || prev === current.left) {
prev = current
next = current.right
}
// 如果上次遍历节点是当前节点的右节点
// 则结束当前节点遍历,返回上层节点开始遍历
if (!next || prev === current.right) {
prev = current,
next = current.parent
}
current = next
}
}
DLRSearch(bt)
// 中序优先遍历
const ldr = document.getElementById('LDR')
function LDRSearch(node) {
let prev
let next
let current = node
while(current) {
// 如果上次遍历节点是当前节点的父节点
// 则开始当前节点子节点的遍历
if (prev === current.parent) {
prev = current
next = current.left
}
// 如果上次遍历节点是当前节点的左节点
// 则开始右节点遍历
if (!next || prev === current.left) {
const p = document.createElement('p')
p.innerText = current.value
ldr.appendChild(p)
prev = current
next = current.right
}
// 如果上次遍历节点是当前节点的右节点
// 则结束当前节点遍历,返回上层节点开始遍历
if (!next || prev === current.right) {
prev = current,
next = current.parent
}
current = next
}
}
LDRSearch(bt)
// 后序优先遍历
const lrd = document.getElementById('LRD')
function LRDSearch(node) {
let prev
let next
let current = node
while(current) {
// 如果上次遍历节点是当前节点的父节点
// 则开始当前节点子节点的遍历
if (prev === current.parent) {
prev = current
next = current.left
}
// 如果上次遍历节点是当前节点的左节点
// 则开始右节点遍历
if (!next || prev === current.left) {
prev = current
next = current.right
}
// 如果上次遍历节点是当前节点的右节点
// 则结束当前节点遍历,返回上层节点开始遍历
if (!next || prev === current.right) {
const p = document.createElement('p')
p.innerText = current.value
lrd.appendChild(p)
prev = current,
next = current.parent
}
current = next
}
}
LRDSearch(bt)
</script>
</body>
</html>
这样我们就通过循环的方式实现了二叉树的遍历,不过前提是二叉树要是三叉链表存储的二叉树。
总结
通过这篇总结,我们算是对二叉树及其遍历有了一个了解,二叉树的应用场景还是比较多的,后面会将其针对一个场景做应用。